Week 4 : Two-Sample t-tests
This week we will explore how to use Jamovi to test hypotheses about a dataset using t-tests. We will touch on some revision from previous weeks so please do jump back to past computer practicals for revision if required
| Quantitative Methods | |
|---|---|
| Independent samples t-tests | |
| Paired samples t-tests | |
| Assumptions of parametric tests |
| Data Skills | |
|---|---|
| Computing a new variable from existing data | |
| Computing checks for normality and homogeneity of variance |
| Open Science | |
|---|---|
| Exploring and understanding new datasets |
1. The Dataset
We’ll be working with the dataset we collected after the break during the lecture in Week 3. This is a partial replication of a study published in the journal Psychological Science (Miller et al. 2023). The original paper found the following results summarised in the abstract.
Recent evidence shows that AI-generated faces are now indistinguishable from human faces. However, algorithms are trained disproportionately on White faces, and thus White AI faces may appear especially realistic. In Experiment 1 (N = 124 adults), alongside our reanalysis of previously published data, we showed that White AI faces are judged as human more often than actual human faces—a phenomenon we term AI hyperrealism. Paradoxically, people who made the most errors in this task were the most confident (a Dunning-Kruger effect). In Experiment 2 (N = 610 adults), we used face-space theory and participant qualitative reports to identify key facial attributes that distinguish AI from human faces but were misinterpreted by participants, leading to AI hyperrealism. However, the attributes permitted high accuracy using machine learning. These findings illustrate how psychological theory can inform understanding of AI outputs and provide direction for debiasing AI algorithms, thereby promoting the ethical use of AI.
We ran a quiz that students in the lecture could join on their phones/laptops. There were two parts to the quiz:
The faces section included 12 faces that were either photographs or real people or AI generated images of people. The stimuli were taked from the materials released by (Miller et al. 2023) on the Open Science Framework. Responses were either ‘Real person’ or ‘AI generated’.

The confidence section asked participants to rate their confidence in their ability to do the following three things.
- Distinguish real photos of people from AI generated images (Experimental condition)
- Distinguish photos of happy people from photos of sad people (Emotional control condition)
- Distinguish photos of people you used to know in primary school from strangers (Memory control condition)
Scores were recorded on a scale from 1 (Completely confidence) to 10 (Not at all confident). The confidence section was repeated before and after the faces section to see if participants confidence changed as a result of doing the AI faces task
2. The Challenge
This week we will use both one sample and two sample t-tests to explore the following hypotheses.
- People are able to distinguish AI generated faces from real photos of humans.
- Confident people are better at distinguishing AI faces from real faces.
- People’s confidence in distinguishing AI generated faces will reduce after performing the task, but their confidence about emotion perception and memory will not change.
Take a moment to think about these hypotheses. Which statistical test is most appropriate for each? Do they call for a one-tailed or a two-tailed test?
2. Exploring the data
It is critical to take some time to understand the data we work with before running critical hypothesis tests. Here we’ll take a look through the dataset to understand what information is present and if we’re happy to proceed with the analysis. This is similar to what we did in week 1 - you can refer back to the week 1 materials for additional guidance if you need it.
Before going any further, the data file rmb-week-3_lecture-quiz-data_ai-faces-2026.csv into a new Jamovi session.
Take a read through the data columns. We have 26 in total with the following information.
| Column Names | Description |
|---|---|
First Name |
Participant ID - always ‘Anonymous’ |
DataUse |
Participant response to data re-use question |
AIConfidenceBefore |
Confidence in distinguishing AI faces from real BEFORE the task : 1 (Completely confident) to 10 (Not at all confident) |
EmoConfidenceBefore |
Confidence in distinguishing happy from sad faces BEFORE the task (Emotional control) : 1 (Completely confidence) to 10 (Not at all confident) |
MemoryConfidenceBefore |
Confidence in recognising a face from a long time ago BEFORE the task (Memory control) : 1 (Completely confidence) to 10 (Not at all confident) |
Face1_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face2_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face3_AI |
Result for face (1 is correct response, 0 is incorrect) |
Face4_AI |
Result for face (1 is correct response, 0 is incorrect) |
Face5_AI |
Result for face (1 is correct response, 0 is incorrect) |
Face6_AI |
Result for face (1 is correct response, 0 is incorrect) |
Face7_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face8_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face9_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face10_Real |
Result for face (1 is correct response, 0 is incorrect) |
Face11_AI |
Result for face (1 is correct response, 0 is incorrect) |
Face12_AI |
Result for face (1 is correct response, 0 is incorrect) |
Quiz1 |
Response for revision quiz question |
Quiz2 |
Response for revision quiz question |
Quiz3 |
Response for revision quiz question |
AIConfidenceAfter |
Confidence in distinguishing AI faces from real AFTER the task |
EmoConfidenceAfter |
Confidence in distinguishing happy from sad faces AFTER the task (Emotional control) |
MemoryConfidenceAfter |
Confidence in recognising a face from a long time ago AFTER the task (Memory control) |
Work through the following questions, try to get an answer yourself before clicking to see the result. Data exploration is a critical skill that you’ll need whenever looking a new data throughout your degree.
Fill in the gaps to check your understanding of this dataset.
A total of participants are included in the dataset, of these indicated that they did not want their data to be included in the shared dataset.
We would expect % accuracy if the participants answered randomly on the the Real or AI face discrimination.
The columns containing the responses for each face have a 0 when the participant was incorrect and a 1 when the participant was correct for that face.
Compute desriptive statistics for all 12 faces and look at the ‘Mean’.
This indicates the proportion of participants that correctly identified whether the fact was of a real person or generated by AI. This can be converted to a percentage by multiplying it by 100.
You can use Descriptive Statistics to answer the following questions.
Fill in the gaps to check your understanding of this dataset.
The most accurately identified image was face , which was correctly identified as % of the time. A total of participants did NOT give a response for this face.
The least accurately identified image was face , which was correctly identified as % of the time. A total of participants did NOT give a response for this face.
Open a new desriptive statistics tab and compute descriptives for the six confidence questions (3 were before the faces, and 3 were afterwards).
The questions asked how confidence you were that you can do the following:
- Distinguish real photos of people from AI generated images (AI)
- Distinguish photos of happy people from sad people (Emotion)
- Distinguish phtotos of people you used to know in primary school from strangers (Memory)
The confidence scale ranges from 1 to 9, in which 1 means ‘Completely Confident’ and 9 means ‘Not at all confident’.
Take a moment to get familiar with the outputs.
Use the descriptive statistics on the confidence questions to fill in the gaps, you may have to compute some additional descriptive statistics along the way.
Before the face task, participants were most confident in their ability to distinguish with an average confidence of and 95% confidence intervals ranging from a lower bound of to an upper bound of
Participants were least confident in their ability to distinguish with an average confidence of and 95% confidence intervals ranging from a lower bound of to an upper bound of
Comparing confidence before and after the fact task, confidence in indentifying AI faces from real faces from before to afterwards.
Confidence in indentifying happy faces from sad faces from before to afterwards.
Confidence in indentifying people you used to know in primary school from strangers from before to afterwards.
3. Computing overall accuracy
The descriptive statistics gave us a good overview of the dataset and we can start working towards testing our hypotheses.
One critical piece of information is missing though! we have accuracy for each individual face but not an overall score for each participant. We’ll need to compute this new variable ourselves from the average accuracy of all twelve faces.
We can define our own variables in Jamovi using the ‘Compute’ function in the ‘Variables’ or the ‘Data’ tabs. Open a new Transformed variable.
This will open a menu with an option to give the new variable an name and description. Name the variable PropFacesCorrect to indicate that it contatins the proportion of faces that the participant responded correctly on. You can add a description if you like though this is optional.
The variable is defined within the formula box below the name definitions. We want to compute the average accuracy across all 12 faces so we can add the formula to compute that into the box.
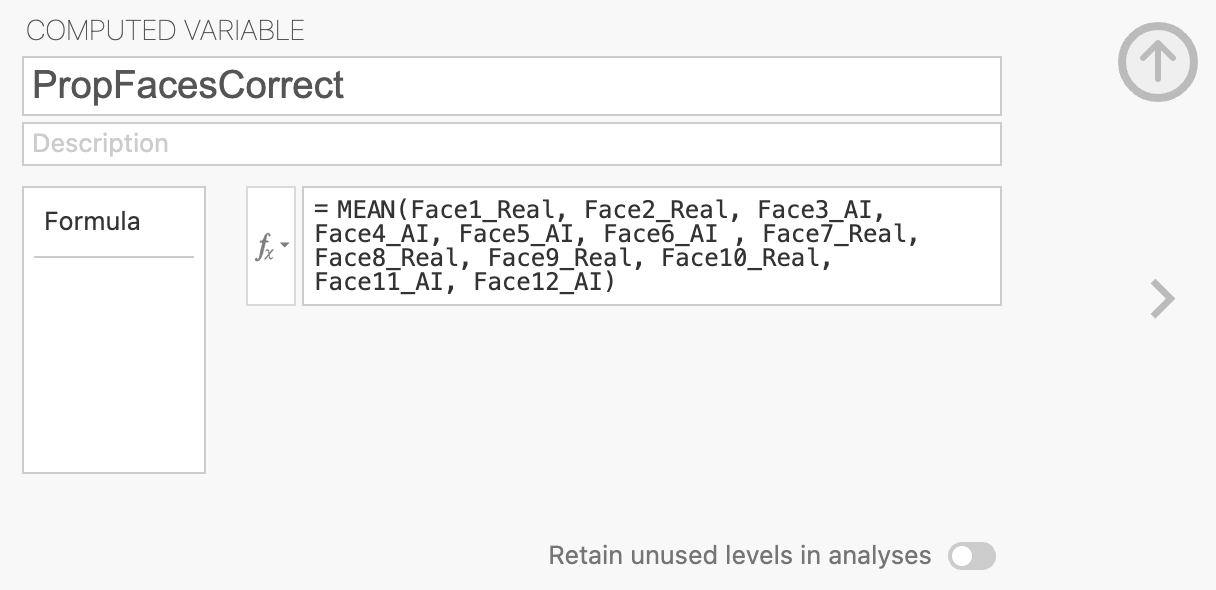
We can use the MEAN function to do this, you can see a list of all available functions by looking in the \(f_x\) drop-down menu. You can click a function to see what it does and double click it to add it to the computed variable.
MEAN will add all the columns together and divide the result by 12 (the total number of faces). Make sure that all the columns are grouped by parentheses! otherwise Jamovi will only divide the final included in a comma separated list within the parentheses.
The formula should look something like this, I’ve removed some faces to simplify the visualisation. You should include them all.
= MEAN(Face1_Real, Face2_Real, ... , Face11_AI, Face12_AI)Once this is complete, you should be able to find your new column of values.
Now, let’s take a look at our new variable.
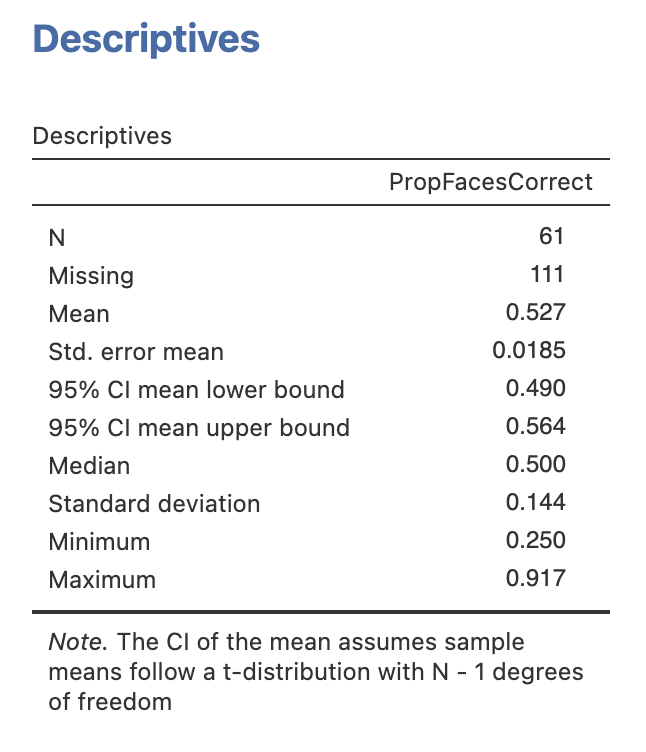
Compute desriptive statistics for the new PropFacesCorrect variable.
Take a moment to explore and understand the results.
Use the descriptive statistics on the PropFacesCorrect to fill in the gaps, you may have to compute some additional descriptive statistics along the way.
A total of participants responded to all 12 faces, with people missing an answer on at least one face
(Note from Andrew: I’ll give more than 10 seconds per face next year!)
The least accurate participant got a proportion of correct, this corresponds to correct responses out of a possible 12.
The most accurate participant got a proportion of correct, this corresponds to correct responses out of a possible 12.
The group average was a proportion of correct responses with a 95% confidence interval between a lower bound of and an upper bound of .
4. Hypothesis 1 - People are able to distinguish AI generated faces from real photos of humans
Ok, we’re ready to test the first hypothesis. Use the information you know about the dataset and try to find an answer!
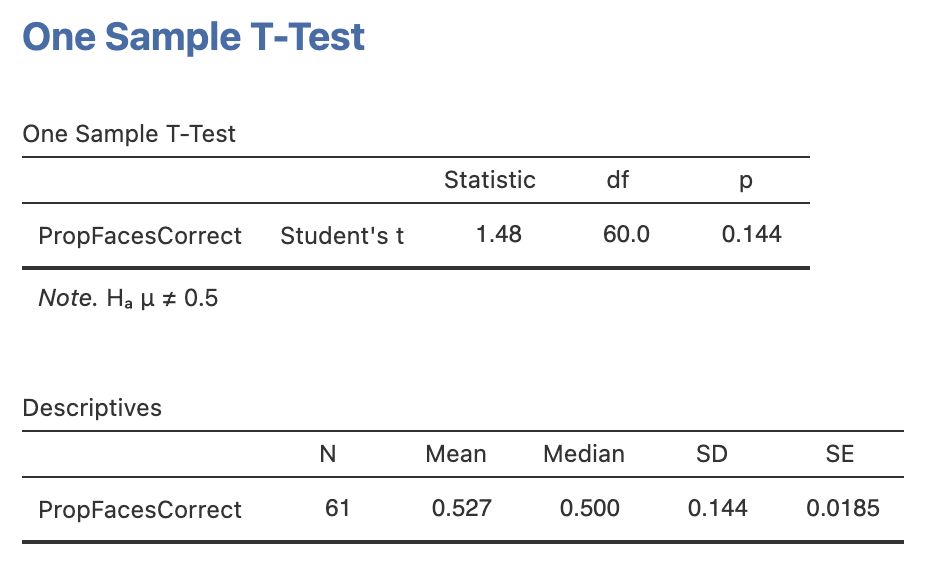
Run a one sample t-test testing whether the proportion of correctly identified faces was above chance level for the group, include some descriptive statistics to help you interpret the result.
Using your results, address the following hypothesis:
People are able to distinguish AI generated faces from real photos of humans
What sort of hypothesis is this and what is the most approprate statistical test?
Compute the statistics, do the data support the experimental or the null hypothesis?
Once you have finished, complete this writing to report the results as if it were in a paper or report.
A one sample t-test comparing the group average proportion of correctly identified faces (M = , SD=) to chance level (proportion correct = ) showed a significant effect, t() = , p=. We can conclude that participants in the experiment were to distinguish AI generated faces from real faces.
The results for your t-test should look like this:
5. Hypothesis 2 - Confident people are better at distinguishing AI faces from real faces.
Now the second hypothesis. We don’t have everything we need to test this hypothesis yet. We’ll need some way to split our participants into two groups - one with high confidence in AI face detection and one with low confidence. Time to compute another variable.
Compute a new variable named ConfidentBefore that separates the groups based on the median AI face detection confidence before the task.
You’ll need the median value for AIConfidenceBefore - you can compute this from descriptive statistics.
The computed variable will need some logical condition (using operators like ‘>’, ‘<’ or ‘==’) that separates participants with confidence above and below the median.
The median value for AIConfidenceBefore is 4, so our computed variable definition will look like this.
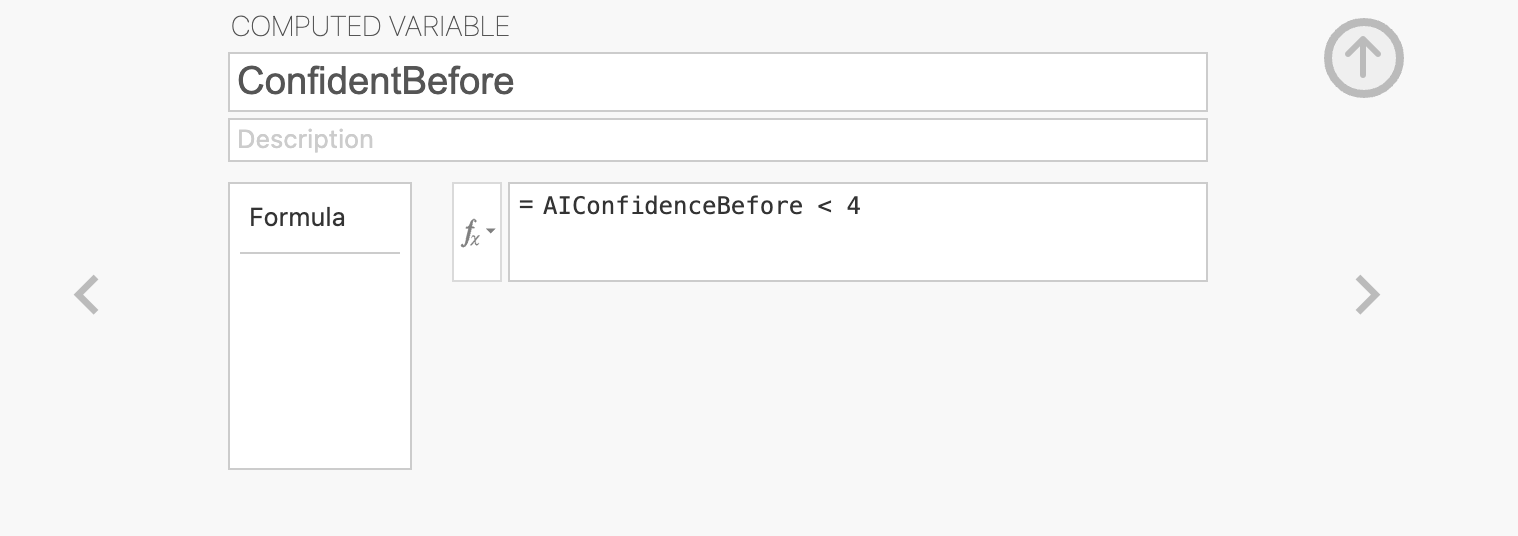
The values in ConfidentBefore will now be ‘True’ for people with high confidence (above 4) and ‘False’ for people with low confidence (below 4). It doesn’t matter if you’ve done this the other way around - the tests will still work but the results will be flipped in the other direction (multiplied by -1)
With our new variable, we have what we need to run an independent samples t-test. This is very straightforward following the analyses we’ve run previously in the module.
Open the ‘Independent Sample t-test’ menu under ‘t-tests’. To run the analysis, drag PropFacesCorrect across as our dependent variable and our new ConfidentBefore variable as the grouping variable. The results should appear on the right automatically.
Add all three variants of the t-test:
- Students t-test
- Welch’s t-test
- Mann-Whitney U test (non-parametric alternative)
add the following options:
- Descriptives
- Homogeneity Test
- Normality Test
Let’s think through the results
Let’s interpret the results. Fill in the blanks with results for the correct statistical test (see the last data-skills drop down question!).
Report the medians if we’re using the Mann-Whitney U test.
| Statistic | Value |
|---|---|
| Statistical Test | |
Test statistic (t or U) |
|
| Degrees of freedom (Ignore for Mann-Whitney U) | |
| p-value | |
| Mean for high confidence (or median) | |
| Mean for low confidence (or median) |
The results mean we should the null hypothesis that people’s confidence does not relate to their ability to distinguish AI generated faces from the faces of real people.
Your results table should look like this:

6. Hypothesis 3 - People’s confidence in their ability to distinguish AI generated faces will reduce after performing the task
Next we want to explore whether performing the face decision task changes peoples confidences in their abililty to detect AI generated faces. Remember that all participants categorised 12 faces with immediate correct/incorrect feedback and made confidence ratings at the start and end of the task.
Open the ‘Paired Sample t-test’ menu under ‘t-tests’. To run the analysis, drag AIConfidenceBefore and AIConfidenceAfter across as our pair of dependent variables. This is the format for running paired samples t-tests, the rest of the options should be familiar from our previous analyses.
Once you have computed the core test, do the same for the EmoConfidence and MemoryConfidence, and add the following options:
- Descriptives
- Normality Test
- Wilcoxon Rank Test (non-parametric alternative)
The results should appear on the right automatically.
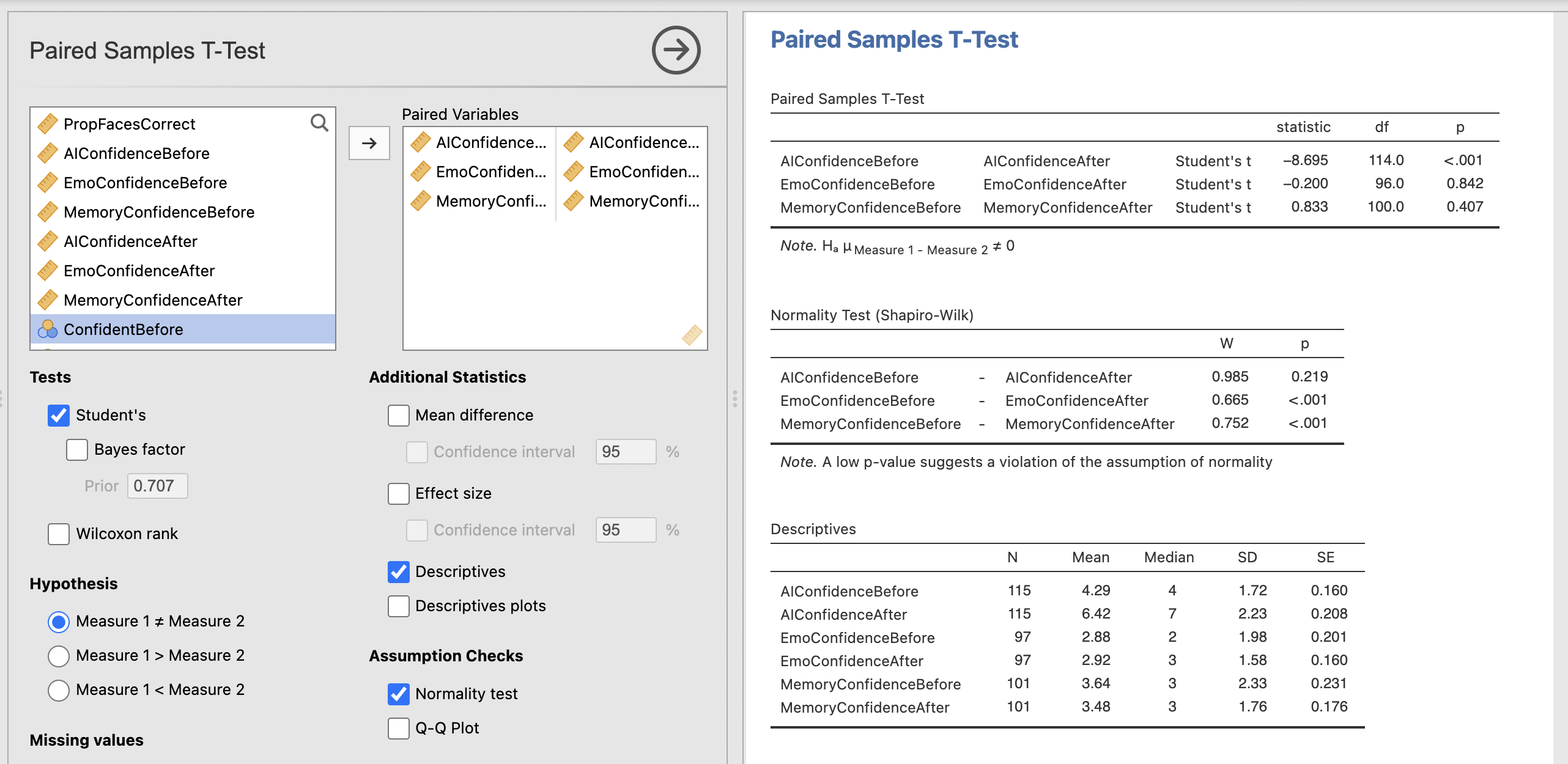
Take a moment to read through and understand the results.
Let’s think through what this all means…
Use your results to fill in the gaps in these results.
A paired samples t-test showed difference in participants confidence in their ability to distinguish AI faces from real faces before (M=, SD=) and after (M=, SD=) the face perception task. t() = , p=. Participant’s confidence was after completing the face task.
The Shapio-Wilk statistic indicated that the emotional perception scores violated the assumption of normality (W=, p=M=). A Wilcoxon Rank test showed difference in participant’s confidence in their ability to distinguish happy faces from sad faces before (Median=) and after (Median=) the task.
The Shapio-Wilk statistic indicated that the memory scores violated the assumption of normality (W=, p=M=). A Wilcoxon Rank test showed difference in participant’s confidence in their ability to distinguish people you used to know in primary school from strangers before (Median=) and after (Median=) the task.
8. Summary
We’ve computed a range of tests to statistically assess our hypotheses today! One experiment can often yield enough data to run a wide range of analyses. It is always a good idea to start with your hypotheses and predictions to break the analysis down into manageable chunks.